Asset Filter¶
The foglamp-filter-asset is a filter provides a means to alter the flow of assets and datapoints as the data traverses a pipeline. It does not change the values in anyway, but it does allow for the renaming and removal of assets or datapoints within assets. It can also be used to flatten a hierarchical datapoint structure for use with destinations that are unable to handle hierarchical data.
Datapoints may be removed from the stream based on the type of the datapoint, this is useful to remove complex types that elements upstream in the pipeline are unable to handle, for example to remove image data before the stream is sent to a destination that is unable to handle images.
It may be used either in South or North services or North tasks and is driven by a set of rules that defines what actions to take. Multiple rules may be combined within a single invocation of the filter.
Asset filters are added in the same way as any other filters.
Click on the Applications add icon for your service or task.
Select the asset plugin from the list of available plugins.
Name your asset filter.
Click Next and you will be presented with the following configuration page
|
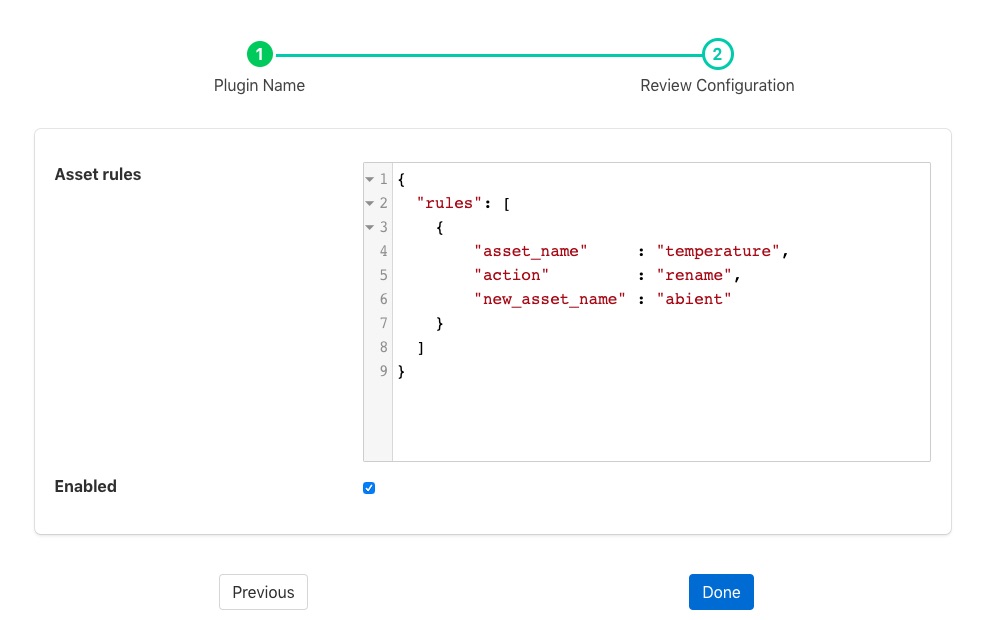
Enter the Asset rules
Enable the plugin and click Done to activate it
Rules¶
The asset rules are an array of JSON requires rules as an array of objects which define the asset name to which the rule is applied and an action. Rules on an asset will be executed in the exact order defined in the JSON array.
There are a number of different rules that may be applied to the readings. Each rule will perform a specific action on the reading and will be applied based upon a match with the asset name within the reading. The rules are configured using a JSON object to define the operation of the rule. Each object contains the asset match criteria and the action name. In addition there are a set of parameters that are passed to the rule.
The common parameters are
asset_name - Either a literal asset name to match or a regular expression.
action - The action the rule will take.
The sections below document the details of each of the different rules and the parameters supported by those actions.
Include Rule¶
This rule takes no extra parameters. If the asset name matches that of the reading then the reading will be included in the output.
{
"asset_name" : "pump417",
"action" : "include"
}
Exclude Rule¶
This rule takes no extra parameters. If the asset name matches that of the reading then the reading will be excluded in the output.
{
"asset_name" : "pump417",
"action" : "exclude"
}
Rename Rule¶
The rename rule takes an extra parameter which is the new name of the asset that will be used for any matching reading.
{
"asset_name" : "pump417",
"action" : "exclude",
"new_asset_name" : "SlurryPump417"
}
If the asset_name property is a regular expression then the rule can be used to rename several assets in a single rule. In this case elements of the matched name can be used in the new name using standard regular expression syntax.
{
"asset_name" : "pump([0-9]*)",
"action" : "exclude",
"new_asset_name" : "SlurryPump$1"
}
In the above example any asset called pump with a numeric suffix will be matched, the new name for the asset will be SlurryPump with the same numeric suffix added. The $1 in the new asset name will be substituted with the matching text of the first bracketed expression in the regular expression given in asset_name.
Remove Rule¶
The remove rule will remove one or more datapoints from a reading. The remove rule must be passed one of a number of parameters that are used to define the datapoints to be removed. These are:
datapoint: Remove datapoints that match the string value of the datapoint property. The value may be a literal datapoint name or a regular expression.
datapoints: remove datapoints that match any of the values given in the array of strings that are the value of the datapoints property. The strings in the array may be a mixture of literal datapoint names or regular expressions.
type: remove datapoints whose type matches the string value of the type property.
To remove a single named datapoint:
{
"asset_name" : "pump[0-9]*",
"action" : "remove",
"datapoint" : "temperature"
}
To remove all datapoint names matching a single regular expression:
{
"asset_name" : "pump[0-9]*",
"action" : "remove",
"datapoint" : ".* temp"
}
To remove a specific set of named datapoints:
{
"asset_name" : "pump[0-9]*",
"action" : "remove",
"datapoints" : [ "case temp", "impeller temp" ]
}
The datapoints property can also contain a mixture of literal names and regular expressions:
{
"asset_name" : "pump[0-9]*",
"action" : "remove",
"datapoints" : [ ".* temp", "current", "voltage" ]
}
The type property can be given to specify that all datapoints of a particular type should be removed. To remove all datapoints of type image the following can be used:
{
"asset_name" : "pump[0-9]*",
"action" : "remove",
"type" : "image"
}
Note
Only one of datapoint, datapoints or type should be specified in a remove rule.
Select Rule¶
The select rule is closely related to the remove rule. However instead of specifying the datapoints that should be removed from the matching readings, it specifies the datapoints that should be retained in the reading.
Note
The action retain can be used as a synonym for the select action.
The select rule takes the same set of optional properties as the remove rule.
datapoint: select datapoints that match the string value of the datapoint property. The value may be a literal datapoint name or a regular expression.
datapoints: select datapoints that match any of the values given in the array of strings that are the value of the datapoints property. The strings in the array may be a mixture of literal datapoint names or regular expressions.
type: select datapoints whose type matches the string value of the type property.
To select a single named datapoint
{
"asset_name" : "pump[0-9]*",
"action" : "select",
"datapoint" : "temperature"
}
To select all datapoint names matching a single regular expression
{
"asset_name" : "pump[0-9]*",
"action" : "retain",
"datapoint" : ".* temp"
}
In the above we have used the synonym retain for the select rule.
To select a specific set of named datapoints
{
"asset_name" : "pump[0-9]*",
"action" : "select",
"datapoints" : [ "case temp", "impeller temp" ]
}
The datapoints property can also contain a mixture of literal names and regular expressions.
{
"asset_name" : "pump[0-9]*",
"action" : "select",
"datapoints" : [ ".* temp", "current", "voltage" ]
}
The type property can be given to specify that all datapoints of a particular type should be retained. To select all datapoints of a numeric type, either integer or floating point, the following can be used.
{
"asset_name" : "pump[0-9]*",
"action" : "select",
"type" : "number"
}
Note
Only one of datapoint, datapoints or type should be specified in a select rule.
Split Rule¶
The split rule is used to process a single reading and split the datapoints from that one reading to create multiple readings. The split action can be passed an optional split property to define how to split the reading.
The split property value is a JSON object that describes how to split the asset into new assets and which datapoints are moved to which new assets. The content is a set of keys with the values for each key being an array of datapoint names. The key name becomes the asset name of the new asset and the values in the array are the datapoints to place in that asset.
As an example if we want to take a single asset that contains electrical data and environmental data and create a pair of assets for the two categories of data, a split rule could be used.
{
"asset_name" : "pump4107",
"action" : "split",
"split" : {
"electrical" : [ "voltage", "current", "power" ],
"environmental" : [ "temperature", "humidity" ]
}
}
This would create two assets, electrical and environmental. Regular expressions can be used to name the new assets. Using the above example and applying it to any pump we could rewrite the split parameters as
{
"asset_name" : "pump([0-9]*)",
"action" : "split",
"split" : {
"electrical$1" : [ "voltage", "current", "power" ],
"environmental$1" : [ "temperature", "humidity" ]
}
}
This would match all pump assets and create two new assets called electrical and environmental with the numeric suffix copied from the pump asset.
Note
It is possible to put the same datapoint in two or more assets created by the split rule.
If no split property is given the reading will be split into a number of readings, each with a single datapoint. The asset name of each of these new readings will be generated by taking the original asset name and appending the datapoint name with an underscore separator. As an example if a reading with an asset name of pump with two datapoints, speed and current is passed to a split rule with no split parameter. The two new readings created would have asset names pump_speed and pump_current.
Flatten Rule¶
The flatten rule will convert an asset that has nested datapoints to a flat format. A nested datapoint is a datapoint that does not contain values, but rather contains one or more datapoints as its values. The flatten rule takes no additional properties to define its operation.
{
"asset_name" : "pump34",
"action" : "flatten"
}
Nest Rule¶
The nest rule will allows datapoints within an asset to be nested below a new datapoint. This allows for a structured asset to be created from a flat asset. The nest asset uses a parameter called nest to define how to nest the data.
The nest property value is a JSON object that describes how to nest the datapoints into new parent datapoints and which datapoints are moved to which new datapoints. The content is a set of keys with the values for each key being an array of datapoint names. The key name becomes the parent datapoint and the values in the array are the datapoints to place under that datapoint.
As an example if we want to take a single asset that contains electrical data and environmental data and create a pair of parent datapoints for the two categories of data, a nest rule could be used.
{
"asset_name" : "pump4107",
"action" : "nest",
"nest" : {
"electrical" : [ "voltage", "current", "power" ],
"environmental" : [ "temperature", "humidity" ]
}
}
Two new datapoints would be created, electrical and environmental. The voltage, current and power datapoints would then be moved to underneath the new electrical datapoint. The temperature and humidity datapoint would be moved below the environmental data points. The result is a hierarchical structure of datapoints within the pump4107 asset.
The nest rule only allows one level of nesting, however, by combining nest rules it is possible to create more deeply nested structures.
{
"asset_name" : "pump4107",
"action" : "nest",
"nest" : {
"electrical" : [ "voltage", "current", "power" ],
"environmental" : [ "temperature", "humidity" ]
}
},
{
"asset_name" : "pump4107",
"action" : "nest",
"nest" : {
"plc" : [ "electrical", "environmental" ]
}
}
The first rule creates a one level deep nesting for the electrical and environmental datapoints. The second then pushed these down a level beneath the plc datapoint.
Note
Care should be taken when nesting datapoints as not all destinations north of FogLAMP are able to handle nested data. Before sending data to those destinations you should always flatten the datapoints first.
Datapoint Map Rule¶
The datapoint map rule is used to map a set names of the datapoints within a reading to a set of new names. The rule takes a map property in the rule configuration that contains a number of old names as the keys and new names as the values in each pair.
{
"asset_name" : "pump4107",
"action" : "datapointmap",
"map" : {
"volts" : "voltage",
"amps" : "current",
"watts" : "power",
"degrees" : "temperature"
}
}
Supported Types¶
The type property of any action that supports it must use one of the predefined type values as listed in the table below.
Supported data types for actions¶ Data type
Details
INTEGER
Integer number
FLOATING
Maps to FLOAT
NUMBER
Both integer and floating point values
NON-NUMERIC
Everything except integer and floating point values
STRING
String of characters
DP_LIST
Datapoint list
DP_DICT
Datapoint dictionary
IMAGE
Image
FLOAT_ARRAY
Float array
2D_FLOAT_ARRAY
Two dimensional float array
BUFFER
Maps to DATABUFFER
ARRAY
FLOAT_ARRAY datapoints
2D_ARRAY
FLOAT_ARRAY datapoints
USER_ARRAY
Both FLOAT_ARRAY and 2D_FLOAT_ARRAY datapoints
NESTED
A synonym for DP_DICT
Note
Datapoint types are case insensitive.
Default Action¶
In addition a defaultAction may be included, however this is limited to include, exclude and flatten. Any asset that does not match a specific rule will have this default action applied to them. If the default action it not given it is treated as if a default action of include had been set.
Examples¶
The following are some examples of how the asset filter may be used.
Remove Assets From The Pipeline¶
We wish to remove the asset called raw from the pipeline, for example if this asset has been used in calculations earlier in the pipeline and is now no longer needed. We can use a rule
{
"rules" : [
{
"asset_name" : "raw",
"action" : "exclude"
}
]
}
As the default is to leave any unmatched asset unaltered in the pipeline the above rule will not impact assets other than raw.
We can change the default action, as an alternative lets saw we use multiple assets in the pipeline to calculate a new asset called quality, we want to remove the assets used to calculate quality but do not wish to name each of them. In this case we can use a rule
{
"rules" : [
{
"asset_name" : "quality",
"action" : "include"
}
],
"defaultAction" : "exclude"
}
Since we have used the defaultAction with exclude, and asset that does not match the rules above will be removed from the pipeline.
Flatten Hierarchical Data¶
Flatten a hierarchy datapoint called pressure that has three children, floor1, floor2 and floor3 within an asset called water.
{
"pressure": { "floor1" : 30, "floor2" : 34, "floor3" : 36 }
}
We can use the rule
{
"rules" : [
{
"asset_name" : "water",
"action" : "flatten"
}
]
}
The datapoint pressure will be flattened and three new data points will be created, pressure_floor1, pressure_floor2 and pressure_floor3. The resultant asset will no longer have the hierarchical datapoint pressure included within it.
Changing Datapoint Names¶
Using a map to change the names of the datapoints within an asset.
Given an asset with the datapoints rpm, X and depth we want to rename them to be motorSpeed, toolOffset and curDepth. We use a map as follows to accomplish this.
{
"rules" : [
{
"asset_name" : "lathe328",
"action" : "datapointmap",
"map" : {
"rpm" : "motorSpeed",
"X" : "toolOffset",
"depth" : "cutDepth"
}
}
]
}
This map will transform the asset as follows
Existing Datapoint name |
New Datapoint Name |
|---|---|
rpm |
motorSpeed |
X |
toolOffset |
depth |
cutDepth |
Remove Named Datapoint From An Asset¶
Suppose we have a vibration sensor that gives us three datapoints for the vibration, X, Y and Z. We use the expression filter earlier in the pipeline to add a new combined vector for the vibration and we now wish to remove the X, Y and Z datapoints. We can do this with the asset filter by uses a set of rules as follows.
{
"rules" : [
{
"asset_name" : "vibration",
"action" : "remove",
"datapoint" : "X"
},
{
"asset_name" : "vibration",
"action" : "remove",
"datapoint" : "Y"
},
{
"asset_name" : "vibration",
"action" : "remove",
"datapoint" : "Z"
}
]
}
The above example can be more succinctly expressed using the datapoints parameter
{
"rules" : [
{
"asset_name" : "vibration",
"action" : "remove",
"datapoints" : [ "X", "Y", "Z" ]
}
]
}
Passing On A Subset Of Datapoints¶
Using the same vibration sensor as above, but we only want to include the X and Y components of vibration. We can filter out the other components, and any other datapoints that might appear in the pipeline by using the select action
{
"rules" : [
{
"asset_name" : "vibration",
"action" : "select",
"datapoints" : [ "X", "Y" ]
}
]
}
We could accomplish the removal of the Z datapoint by using the remove action,
{
"rules" : [
{
"asset_name" : "vibration",
"action" : "remove",
"datapoint" : "Z"
}
]
}
However the select action has the added benefit if other datapoints were to appear in the pipeline they would be blocked by this action.
Note
If a reading is missing one or more of the datapoints in the select actions datapoints list then only those datapoints that exist in the reading and the datapoints list will be passed onwards in the pipeline. No error or warning will be raised by the asset filter for missing datapoints.
Removing Image Data From Pipelines¶
In this example we have a pipeline that ingests images from a camera, passes them through image processing filters and a computer vision filter that produces metrics based on the image content. We want to send those metric to upstream systems but these systems do not support image data. We can use the asset filter to remove all image type datapoints from the pipeline.
{
"rules" : [
{
"asset_name" : "camera1",
"action" : "remove",
"type" : "image"
}
]
}
Split an asset into multiple assets¶
In this example an asset named lathe1014 will be split into multiple assets asset1, asset2 and asset3.
New asset asset1 will have datapoints a, b and f from asset lathe1014
New asset asset2 will have datapoints a, e and g from asset lathe1014
New asset asset3 will have datapoints b and d from asset lathe1014
{
"rules" : [
{
"asset_name" : "lathe1014",
"action" : "split",
"split" : {
"asset1" : [ "a", "b", "f"],
"asset2" : [ "a", "e", "g"],
"asset3" : [ "b", "d"]
}
}
]
}
Note: If split key is missing then one new asset per datapoint will be created. The name of new asset will be the original asset name with the datapoint name appended following an underscore separator.
Combining Rules¶
Rules may be combined to perform multiple operations in a single stage of a pipeline, the following example shows such a situation.
{
"rules": [
{
"asset_name": "Random1",
"action": "include"
},
{
"asset_name": "Random2",
"action": "rename",
"new_asset_name": "Random92"
},
{
"asset_name": "Random3",
"action": "exclude"
},
{
"asset_name": "Random4",
"action": "rename",
"new_asset_name": "Random94"
},
{
"asset_name": "Random5",
"action": "exclude"
},
{
"asset_name": "Random6",
"action": "rename",
"new_asset_name": "Random96"
},
{
"asset_name": "Random7",
"action": "include"
},
{
"asset_name": "Random8",
"action": "flatten"
},
{
"asset_name": "lathe1004",
"action": "datapointmap",
"map": {
"rpm": "motorSpeed",
"X": "toolOffset",
"depth": "cutDepth"
}
},
{
"asset_name": "Random6",
"action": "remove",
"datapoint": "sinusoid_7"
},
{
"asset_name": "Random6",
"action": "remove",
"type": "FLOAT"
}
],
"defaultAction": "include"
}
It is possible to have multiple rules applied to the same reading. Care should be taken however with the ordering of the rules. Rules are applied in the order they are defined in the configuration of the filter. In most cases this is not important, however there are three exceptions to this, the rename, the datapointmap and the nest rules.
If the rename rule is used then the reading will be matched for subsequent rules will use the new asset name. In the example below the select rule will never be matched as the rename rule will change the asset name before the match is performed.
{
"rules" : [
{
"asset_name" : "pump42",
"action" : "rename",
"new_asset_name" : "CirculationPump"
},
{
"asset_name" : "pump42",
"action" : "select",
"datapoints" : [ "current", "speed", "flowrate" ]
}
]
}
Before the second select rule is matched, the reading will already have changed asset name and hence the rule will hence not be matched. Reversing the ordering of the rules will result in both rules being applied to the reading as the select rule will be executed first and then the asset will be renamed.
{
"rules" : [
{
"asset_name" : "pump42",
"action" : "select",
"datapoints" : [ "current", "speed", "flowrate" ]
},
{
"asset_name" : "pump42",
"action" : "rename",
"new_asset_name" : "CirculationPump"
}
]
}
Regular Expressions¶
Regular expression can be used for asset_name values in the JSON. Datapoint values within the remove and select actions can also use a regular expression. Regular expressions may also be used to match and replace names in the rename, datapointmap and split rules. In the following example, any datapoint which starts with “Pressure” will be removed from all the assets.
{
"rules": [
{
"asset_name": ".*",
"action": "remove",
"datapoint": "Pressure.*"
}
],
"defaultAction": "include"
}
The filter supports the standard Linux regular expression syntax
Expression |
Description |
|---|---|
. |
Matches any character |
[a-z] |
Matches any characters in the range between the two given |
* |
Matches zero or more occurrences of the previous item |
+ |
Matches one or more occurrence of the previous item |
? |
Matches zero or one occurrence of the previous item |
^ |
Matches the start of the string |
$ |
Matches the end of the string |
d |
Matches any digit (equivalent to [0-9]) |
Enclosing part of an expression in () characters will allow that portion to be reused when substituting a new value. Each bracketed expression may be used in the substitution string by using the $ character following by the bracketed expression number, i.e. the first bracketed expression is $1, the second $2 and so forth.
Examples¶
To match a word, defined as one or more letters, we can use the regular expression
[A-Za-z].*
If we wanted to match capitalised words only then we could use
[A-Z].*
If we wanted to match only words starting with an a or b character there are a number of ways we could do this
[ab][a-z].*
or
a|b[a-z].*
If we wanted to match the words starting with Tank we can use the ^ operator
^Tank
If we wanted to match the words spark and sparks we can use the ? operator
spark.?
If we wanted to match the words camera_1 we can use the d operator
camera_\\d
The above are a few examples of regular expressions that can be used, but serve to illustrate the most used operators that are available.
See Also¶
foglamp-filter-ADM_LD_prediction - Filter to detect whether a large discharge is required for a centrifuge
foglamp-filter-amber - A FogLAMP filter to pass data to the Boon Logic Nano clustering engine
foglamp-filter-asset-conformance - A plugin for performing basic sanity checking on the data flowing in the pipeline.
foglamp-filter-asset-join - Filter to join two assets together to create a single asset
foglamp-filter-asset-validation - A plugin for performing basic sanity checking on the data flowing in the pipeline.
foglamp-filter-batch-label - A filter to attach batch labels to the data. Batch numbers are updated based on conditions seen in the data stream.
foglamp-filter-breakover - Filter to forecast the a pending breakover event in a centrifuge.
foglamp-filter-change - A FogLAMP processing filter plugin that only forwards data that changes by more than a configurable amount
foglamp-filter-conditional-labeling - Attach labels to the reading data based on a set of expressions matched against the data stream.
foglamp-filter-delta - A FogLAMP processing filter plugin that removes duplicates from the stream of data and only forwards new values that differ from previous values by more than a given tolerance
foglamp-filter-downsample - A data downsampling filter which may be used to reduce the data rate using sampling or averaging techniques.
foglamp-filter-ednahint - A hint filter for controlling how data is written using the eDNA north plugin to AVEVA’s eDNA historian
foglamp-filter-enumeration - A filter to map between symbolic names and numeric values in a datapoint.
foglamp-filter-expression - A FogLAMP processing filter plugin that applies a user define formula to the data as it passes through the filter
foglamp-filter-fft - A FogLAMP processing filter plugin that calculates a Fast Fourier Transform across sensor data
foglamp-filter-inventory - A plugin that can inventory the data that flows through a FogLAMP pipeline.
foglamp-filter-log - A FogLAMP filter that converts the readings data to a logarithmic scale. This is the example filter used in the plugin developers guide.
foglamp-filter-md5 - FogLAMP md5 filter computes a MD5 hash of a reading’s JSON representation and stores the hash as a new datapoint within the reading.
foglamp-filter-md5verify - FogLAMP MD5 Verify plugin verifies the integrity of readings by computing a new MD5 hash and comparing it against the stored MD5 datapoint.
foglamp-filter-metadata - A FogLAMP processing filter plugin that adds metadata to the readings in the data stream
foglamp-filter-normalise - Normalise the timestamps of all readings that pass through the filter. This allows data collected at different rate or with skewed timestamps to be directly compared.
foglamp-filter-omfhint - A filter plugin that allows data to be added to assets that will provide extra information to the OMF north plugin.
foglamp-filter-python35 - A FogLAMP processing filter that allows Python 3 code to be run on each sensor value.
foglamp-filter-rate - A FogLAMP processing filter plugin that sends reduced rate data until an expression triggers sending full rate data
foglamp-filter-regex - Regular expression filter to match & replace the string datapoint values
foglamp-filter-rename - A FogLAMP processing filter that is used to modify the name of an asset, datapoint or both.
foglamp-filter-rms - A FogLAMP processing filter plugin that calculates RMS value for sensor data
foglamp-filter-sam - A single Asset Model filter for creating a semantic model of an asset from one or more data sources
foglamp-filter-scale - A FogLAMP processing filter plugin that applies an offset and scale factor to the data
foglamp-filter-scale-set - A FogLAMP processing filter plugin that applies a set of sale factors to the data
foglamp-filter-sha2 - FogLAMP sha2 filter computes a SHA-2 hash of a reading’s JSON representation and stores the hash as a new datapoint within the reading.
foglamp-filter-sha2verify - FogLAMP SHA2 Verify plugin verifies the integrity of readings by computing a new SHA-2 hash and comparing it against the stored SHA-2 datapoint.
foglamp-filter-sigmacleanse - A data cleansing plugin that removes data that differs from the mean value by more than x sigma
foglamp-filter-specgram - FogLAMP filter to generate spectrogram images for vibration data
foglamp-filter-statistics - Generic statistics filter for FogLAMP data that supports the generation of mean, mode, median, minimum, maximum, standard deviation and variance.
foglamp-filter-vibration_features - A filter plugin that takes a stream of vibration data and generates a set of features that characterise that data
foglamp-south-Expression - A FogLAMP south plugin that uses a user define expression to generate data