Consolidation Filter Plugin¶
Overview¶
The Consolidation Filter is designed to consolidate multiple asset readings into a single reading. This is particularly useful for reducing the number of MQTT messages sent when processing statistics history data or any scenario where multiple assets need to be combined.
The filter monitors incoming assets and stores them in a buffer until one of two events occurs:
Duplicate Asset Detection: When an asset name that already exists in the buffer is encountered
Timeout: When a configured timeout period has elapsed since the oldest asset in the buffer was received
When either event occurs, all buffered readings are consolidated into a single reading and sent onwards. The buffer is then cleared and the process repeats.
On shutdown, any remaining buffered readings are automatically flushed and sent.
Configuration¶
|
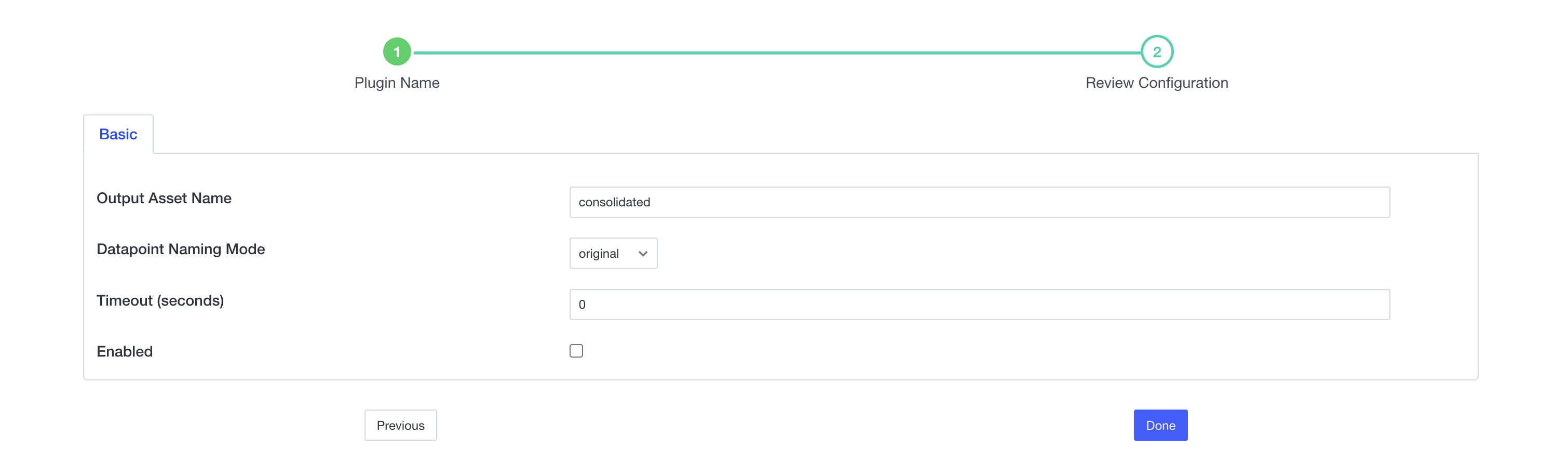
The filter supports the following configuration options:
- enable (boolean, default: false)
Enable or disable the filter execution.
- assetName (string, default: “consolidated”)
The name of the asset to use for the consolidated reading output.
- datapointNaming (enumeration, default: “original”)
Specifies how datapoints in the consolidated reading should be named:
original: Use the original datapoint name. If a name clash occurs (same datapoint name from different assets), an error is logged and the conflicting datapoint is skipped.
prepend: Prepend the asset name to the datapoint name, separated by an underscore. For example, if asset “sensor1” has datapoint “value”, the consolidated datapoint will be named “sensor1_value”.
asset: Use the asset name as the datapoint name. This mode requires that each reading contains exactly one datapoint. If a reading has multiple datapoints, an error is logged and the reading is skipped.
- timeout (integer, default: 0)
Timeout in seconds. If set to a positive value, the filter will automatically flush the buffer when the timeout period has elapsed since the oldest asset in the buffer was received. If set to 0, the timeout mechanism is disabled and the filter will only flush on duplicate asset detection.
Use Cases¶
Statistics History Consolidation: Combine multiple statistics assets into a single consolidated message to reduce MQTT traffic.
Batch Processing: Accumulate readings from multiple assets over a time period before sending them as a batch.
Data Aggregation: Combine related readings from different sources into a unified output format.
Examples¶
Example 1: Basic Consolidation¶
- Configuration:
enable: true assetName: “statistics” datapointNaming: “prepend” timeout: “”
This configuration will: - Consolidate readings when a duplicate asset name is detected - Name output asset as “statistics” - Prepend asset names to datapoint names (e.g., “cpu_temperature” + “value” = “cpu_temperature_value”) - No timeout (only flushes on duplicate detection)
Example 2: Time-based Consolidation¶
- Configuration:
enable: true assetName: “batch” datapointNaming: “original” timeout: “60”
This configuration will: - Consolidate readings every 60 seconds OR when a duplicate is detected (whichever occurs first) - Name output asset as “batch” - Use original datapoint names (will skip on name clashes) - Timeout is set to 60 seconds
Example 3: Asset Name as Datapoint¶
- Configuration:
enable: true assetName: “combined” datapointNaming: “asset” timeout: “30”
This configuration will: - Consolidate readings every 30 seconds OR when a duplicate is detected - Name output asset as “combined” - Use asset name as the datapoint name (requires single datapoint per reading) - Timeout is set to 30 seconds
Notes¶
The filter does not require predefined knowledge of the assets it will process
Each reading in the buffer is stored independently until consolidation
On shutdown, all remaining buffered readings are automatically sent
The timestamp of the consolidated reading is set to the current time
Original reading timestamps are preserved in the buffered copies but the final consolidated reading uses the current timestamp
See Also¶
foglamp-filter-asset - A FogLAMP processing filter that is used to block or allow certain assets to pass onwards in the data stream
foglamp-filter-asset-conformance - A plugin for performing basic sanity checking on the data flowing in the pipeline.
foglamp-filter-asset-join - Filter to join two assets together to create a single asset
foglamp-filter-asset-validation - A plugin for performing basic sanity checking on the data flowing in the pipeline.
foglamp-filter-batch-label - A filter to attach batch labels to the data. Batch numbers are updated based on conditions seen in the data stream.
foglamp-filter-conditional-labeling - Attach labels to the reading data based on a set of expressions matched against the data stream.
foglamp-filter-ednahint - A hint filter for controlling how data is written using the eDNA north plugin to AVEVA’s eDNA historian
foglamp-filter-enumeration - A filter to map between symbolic names and numeric values in a datapoint.
foglamp-filter-expression - A FogLAMP processing filter plugin that applies a user define formula to the data as it passes through the filter
foglamp-filter-fft - A FogLAMP processing filter plugin that calculates a Fast Fourier Transform across sensor data
foglamp-filter-inventory - A plugin that can inventory the data that flows through a FogLAMP pipeline.
foglamp-filter-metadata - A FogLAMP processing filter plugin that adds metadata to the readings in the data stream
foglamp-filter-normalise - Normalise the timestamps of all readings that pass through the filter. This allows data collected at different rate or with skewed timestamps to be directly compared.
foglamp-filter-omfhint - A filter plugin that allows data to be added to assets that will provide extra information to the OMF north plugin.
foglamp-filter-partition - Partition filter plugin for splitting string datapoints into multiple new datapoint.
foglamp-filter-python35 - A FogLAMP processing filter that allows Python 3 code to be run on each sensor value.
foglamp-filter-regex - Regular expression filter to match & replace the string datapoint values
foglamp-filter-rename - A FogLAMP processing filter that is used to modify the name of an asset, datapoint or both.
foglamp-filter-rms - A FogLAMP processing filter plugin that calculates RMS value for sensor data
foglamp-filter-sam - A single Asset Model filter for creating a semantic model of an asset from one or more data sources
foglamp-filter-scale - A FogLAMP processing filter plugin that applies an offset and scale factor to the data
foglamp-filter-scale-set - A FogLAMP processing filter plugin that applies a set of sale factors to the data
foglamp-filter-sigmacleanse - A data cleansing plugin that removes data that differs from the mean value by more than x sigma
foglamp-filter-statistics - Generic statistics filter for FogLAMP data that supports the generation of mean, mode, median, minimum, maximum, standard deviation and variance.