Asset Conformance Filter¶
The foglamp-filter-asset-conformance filter allows simple conformance rules on a readings within a pipeline such that readings that are invalidated can be identified and dealt with appropriately, or discarded early in the processing of the readings.
The filter works by executing a number of conformance rules, defined in the configuration of the plugin, against a single reading. If any of those conformance rule evaluates to false then the asset is considered to have failed validation and a user defined action will be instigated. Supported actions are
Label all readings
Label failed readings
Change asset name
Remove reading
Filter Configuration¶
|

The configuration options supported by the asset-conformance filter are
Asset: The name of the asset to which conformance should be applied. This can be a regular expression match.
Rules: A list of conformance rules. These rules should evaluate to true or false. A value of false represents a failed validation. Each conformance rule consists of the following components:
|
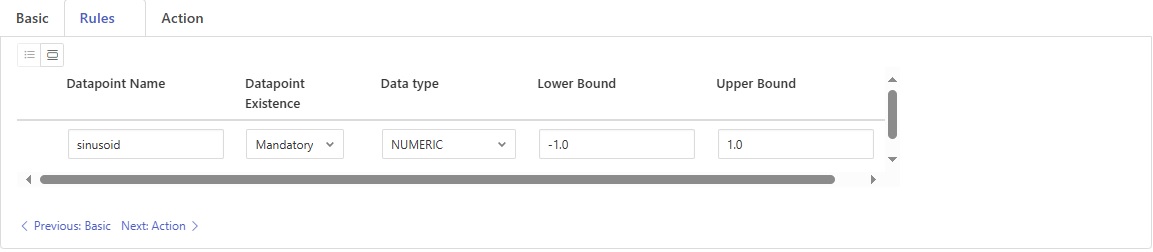
Datapoint Name: The name of the datapoint to validate.
Datapoint Existence: Existence check for the datapoint. If set to true, the datapoint must exist in the reading for the conformance rule to be evaluated true.
Data type: The data type of the datapoint to validate.
Lower Bound: The lower bound for the datapoint value. If set, the value must be greater than or equal to this bound.
Upper Bound: The upper bound for the datapoint value. If set, the value must be less than or equal to this bound.
Action : The filter can take number of actions if conformance rule is not validated
|
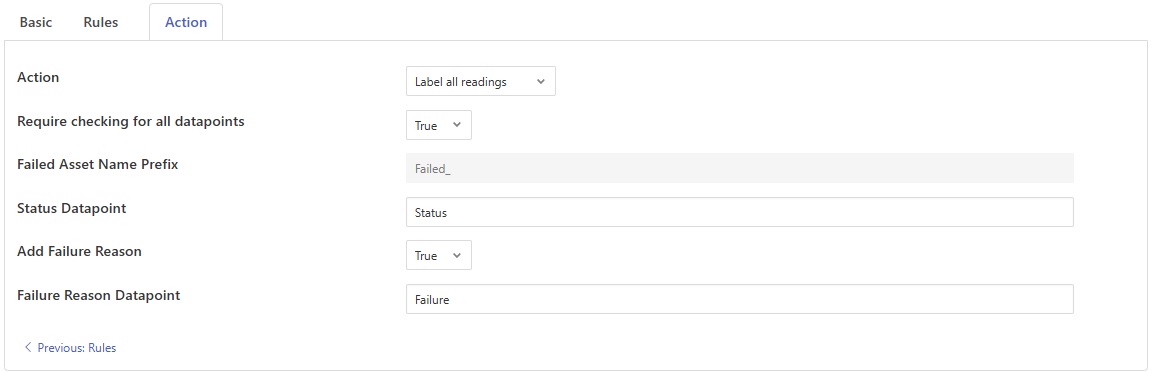
Action: An action to be taken against the conformance rule checks
Label all readings: Label all readings with a pass/fail status by adding a datapoint to the asset in the reading.
Label failed readings: Label readings that have failed validation by adding a datapoint to the asset in the reading.
Change asset name: Change the asset name of readings that have failed validation.
Remove reading: Remove readings that have failed validation from the pipeline.
Require checking for all datapoints: Mark failed if any datapoint does not have an associated check.
Failed Asset Name Prefix: The prefix to be used for asset if validation failed.
Status Datapoint: The name of the datapoint to label pass/fail conditions in a reading. This is applicable only for the action “Label all readings” and “Label failed readings”.
Add Failure Reason: Option to include a reason for conformance failure in a reading. If set to true, a datapoint will be added into the reading for reason of failed validation. If set to false, reason for failed validation will not be added.
Failure Reason Datapoint: The name of the datapoint to label the reason for failure.
Regular Expressions¶
The filter supports the standard Linux regular expression syntax for the asset name.
Expression |
Description |
|---|---|
. |
Matches any character |
[] |
Matches any of the characters enclosed in the brackets |
[a-z] |
Matches any characters in the range between the two given |
* |
Matches zero or more occurrences of the previous item |
+ |
Matches one or more occurrence of the previous item |
? |
Matches zero or one occurrence of the previous item |
{i, j} |
Matches between i and j occurrences of the previous item. Where i and j are integers. |
^ |
Matches the start of the string |
$ |
Matches the end of the string |
See Also¶
foglamp-filter-amber - A FogLAMP filter to pass data to the Boon Logic Nano clustering engine
foglamp-filter-asset-validation - A plugin for performing basic sanity checking on the data flowing in the pipeline.
foglamp-filter-batch-label - A filter to attach batch labels to the data. Batch numbers are updated based on conditions seen in the data stream.
foglamp-filter-conditional-labeling - Attach labels to the reading data based on a set of expressions matched against the data stream.
foglamp-filter-consolidation - A Filter plugin that consolidates readings from multiple assets into a single reading
foglamp-filter-ednahint - A hint filter for controlling how data is written using the eDNA north plugin to AVEVA’s eDNA historian
foglamp-filter-enumeration - A filter to map between symbolic names and numeric values in a datapoint.
foglamp-filter-expression - A FogLAMP processing filter plugin that applies a user define formula to the data as it passes through the filter
foglamp-filter-fft - A FogLAMP processing filter plugin that calculates a Fast Fourier Transform across sensor data
foglamp-filter-inventory - A plugin that can inventory the data that flows through a FogLAMP pipeline.
foglamp-filter-md5 - FogLAMP md5 filter computes a MD5 hash of a reading’s JSON representation and stores the hash as a new datapoint within the reading.
foglamp-filter-md5verify - FogLAMP MD5 Verify plugin verifies the integrity of readings by computing a new MD5 hash and comparing it against the stored MD5 datapoint.
foglamp-filter-metadata - A FogLAMP processing filter plugin that adds metadata to the readings in the data stream
foglamp-filter-name-conformance - A FogLAMP filter plugin to enforce unified namespace conformance by validating asset and datapoint names using pattern or lookup rules, with flexible actions for non-conformance.
foglamp-filter-omfhint - A filter plugin that allows data to be added to assets that will provide extra information to the OMF north plugin.
foglamp-filter-partition - Partition filter plugin for splitting string datapoints into multiple new datapoint.
foglamp-filter-rms - A FogLAMP processing filter plugin that calculates RMS value for sensor data
foglamp-filter-scale - A FogLAMP processing filter plugin that applies an offset and scale factor to the data
foglamp-filter-scale-set - A FogLAMP processing filter plugin that applies a set of sale factors to the data
foglamp-filter-sha2 - FogLAMP sha2 filter computes a SHA-2 hash of a reading’s JSON representation and stores the hash as a new datapoint within the reading.
foglamp-filter-sha2verify - FogLAMP SHA2 Verify plugin verifies the integrity of readings by computing a new SHA-2 hash and comparing it against the stored SHA-2 datapoint.
foglamp-filter-sigmacleanse - A data cleansing plugin that removes data that differs from the mean value by more than x sigma
foglamp-filter-statistics - Generic statistics filter for FogLAMP data that supports the generation of mean, mode, median, minimum, maximum, standard deviation and variance.