Metadata Filter¶
The foglamp-filter-metadata filter allows data to be added to assets within FogLAMP. Metadata takes the form of fixed data points that are added to an asset used to add context to the data. Examples of metadata might be unit of measurement information, location information or identifiers for the piece of equipment to which the measurement relates.
A metadata filter may be added to either a south service or a north task. In a south service it will be adding data for just those assets that originate in that service, in which case it probably relates to a single machine that is being monitored and would add metadata related to that machine. In a north task it causes metadata to be added to all assets that the FogLAMP is sending to the up stream system, in which case the metadata would probably related to that particular FogLAMP instance. Adding metadata in the north is particularly useful when a hierarchy of FogLAMP systems is used and an audit trail is required with the data or the individual FogLAMP systems related to some physical location information such s building, floor and/or site.
To add a metadata filter
Click on the Applications add icon for your service or task.
Select the metadata plugin from the list of available plugins.
Name your metadata filter.
Click Next and you will be presented with the following configuration page
|
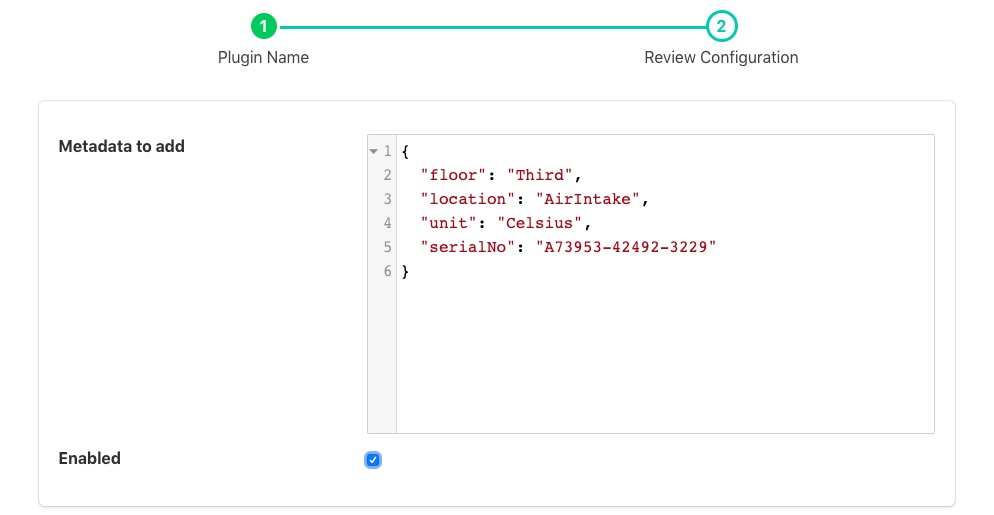
Enter your metadata in the JSON array shown. You may add multiple items in a single filter by separating them with commas. Each item takes the format of a JSON key/value pair and will be added as data points within the asset.
Enable the filter and click on Done to activate it
Macro Substitution¶
The metadata values may use macro substitution to include the values of other datapoints in the new metadata or the name of the asset. Macros are introduced by the use of $ characters and surround the name of the datapoint to substitute into the metadata.
Let us assume we have a datapoint called unit which is the number of the camera attached to our system and we want to have a new datapoint called source which is a string and contains the word camera and the unit number of the camera. We can create metadata of the form
{ "source" : "camera $unit$" }
If we wanted to use the asset name of the reading in the metadata, we could use the reserve macro $ASSET$
{ "source" : "$ASSET$ $unit$" }
This example also illustrates that we can use multiple substitutions in a single meta data item.
If the datapoint that is named in a macro substitution does not exist, then a blank is replaced with the macro name. It is however possible to provide a default value if the datapoint does not exist.
{ "source" : "$ASSET$ $unit|unknown$" }
In this case we would substitute the value of the unit datapoint if one existed or the string unknown if one did not.
We can use substitution to duplicate a datapoint. Assume we have a datapoint called location that we want to both reserve the original value of but also do some destruction processing of later in the data pipeline. In this example we will use another filter to extract the first portion of the location, lets assume this gives us country information. We duplicate the location datapoint into a country datapoint using the meta filter with the following configuration.
{ "country" : "$location$" }
We now have a datapoint called country that contains the full location. A later filter in the pipeline will edit the value of this datapoint such that it just contains the country.
Example Metadata¶
Assume we are reading the temperature of air entering a paint booth. We might want to add the location of the paint booth, the booth number, the location of the sensor in the booth and the unit of measurement. We would add the following configuration value
{
"value": {
"floor": "Third",
"booth": 1,
"units": "C",
"location": "AirIntake"
}
}
In above example the filter would add “floor”, “booth”, “units” and “location” data points to all the readings processed by it. Given an input to the filter of
{ "temperature" : 23.4 }
The resultant reading that would be passed onward would become
{ "temperature" : 23.5, "booth" : 1, "units" : "C", "floor" : "Third", "location" : "AirIntake" }
This is an example of how metadata might be added in a south service. Turning to the north now, assume we have a configuration whereby we have several sites in an organization and each site has several building. We want to monitor data about the buildings and install a FogLAMP instance in each building to collect building data. We also install a FogLAMP instance in each site to collect the data from each individual FogLAMP instance per building, this allows us to then send the site data to the head office without having to allow each building FogLAMP to have access to the corporate network. Only the site FogLAMP needs that access. We want to label the data to say which building it came from and also which site. We can do this by adding metadata at each stage.
To the north task of a building FogLAMP, for example the “Pearson” building, we add the following metadata
{
"value" : {
"building": "Pearson"
}
}
Likewise to the “Lawrence” building FogLAMP instance we add the following to the north task
{
"value" : {
"building": "Lawrence"
}
}
These buildings are both in the “London” site and will send their data to the site FogLAMP instance. In this instance we have a north task that sends the data to the corporate headquarters, in this north task we add
{
"value" : {
"site": "London"
}
}
If we assume we measure the power flow into each building in terms of current, and for the Pearson building we have a value of 117A at 11:02:15 and for the Lawrence building we have a value of 71.4A at 11:02:23, when the data is received at the corporate system we would see readings of
{ "current" : 117, "site" : "London", "building" : "Pearson" }
{ "current" : 71.4, "site" : "London", "building" : "Lawrence" }
By adding the data like this it gives as more flexibility, if for example we want to change the way site names are reported, or we acquire a second site in London, we only have to change the metadata in one place.
See Also¶
foglamp-filter-amber - A FogLAMP filter to pass data to the Boon Logic Nano clustering engine
foglamp-filter-asset - A FogLAMP processing filter that is used to block or allow certain assets to pass onwards in the data stream
foglamp-filter-asset-conformance - A plugin for performing basic sanity checking on the data flowing in the pipeline.
foglamp-filter-asset-join - Filter to join two assets together to create a single asset
foglamp-filter-asset-validation - A plugin for performing basic sanity checking on the data flowing in the pipeline.
foglamp-filter-batch-label - A filter to attach batch labels to the data. Batch numbers are updated based on conditions seen in the data stream.
foglamp-filter-conditional-labeling - Attach labels to the reading data based on a set of expressions matched against the data stream.
foglamp-filter-consolidation - A Filter plugin that consolidates readings from multiple assets into a single reading
foglamp-filter-ednahint - A hint filter for controlling how data is written using the eDNA north plugin to AVEVA’s eDNA historian
foglamp-filter-enumeration - A filter to map between symbolic names and numeric values in a datapoint.
foglamp-filter-expression - A FogLAMP processing filter plugin that applies a user define formula to the data as it passes through the filter
foglamp-filter-fft - A FogLAMP processing filter plugin that calculates a Fast Fourier Transform across sensor data
foglamp-filter-inventory - A plugin that can inventory the data that flows through a FogLAMP pipeline.
foglamp-filter-md5 - FogLAMP md5 filter computes a MD5 hash of a reading’s JSON representation and stores the hash as a new datapoint within the reading.
foglamp-filter-normalise - Normalise the timestamps of all readings that pass through the filter. This allows data collected at different rate or with skewed timestamps to be directly compared.
foglamp-filter-omfhint - A filter plugin that allows data to be added to assets that will provide extra information to the OMF north plugin.
foglamp-filter-partition - Partition filter plugin for splitting string datapoints into multiple new datapoint.
foglamp-filter-python35 - A FogLAMP processing filter that allows Python 3 code to be run on each sensor value.
foglamp-filter-regex - Regular expression filter to match & replace the string datapoint values
foglamp-filter-rename - A FogLAMP processing filter that is used to modify the name of an asset, datapoint or both.
foglamp-filter-rms - A FogLAMP processing filter plugin that calculates RMS value for sensor data
foglamp-filter-sam - A single Asset Model filter for creating a semantic model of an asset from one or more data sources
foglamp-filter-scale - A FogLAMP processing filter plugin that applies an offset and scale factor to the data
foglamp-filter-scale-set - A FogLAMP processing filter plugin that applies a set of sale factors to the data
foglamp-filter-sha2 - FogLAMP sha2 filter computes a SHA-2 hash of a reading’s JSON representation and stores the hash as a new datapoint within the reading.
foglamp-filter-sigmacleanse - A data cleansing plugin that removes data that differs from the mean value by more than x sigma
foglamp-filter-statistics - Generic statistics filter for FogLAMP data that supports the generation of mean, mode, median, minimum, maximum, standard deviation and variance.