OMF End Points¶
The OMF Plugin within FogLAMP supports a number of different OMF Endpoints for sending data out of FogLAMP.
PI Web API OMF Endpoint¶
To use the PI Web API OMF endpoint first ensure the OMF option was included in your PI Server when it was installed.
Now go to the FogLAMP user interface, create a new North instance and select the “OMF” plugin on the first screen. In the second screen select the PI Web API as the OMF endpoint.
AVEVA Data Hub¶
The cloud service from AVEVA that allows you to store your data in the AVEVA cloud.
Edge Data Store OMF Endpoint¶
To use the OSIsoft Edge Data Store first install Edge Data Store on the same machine as your FogLAMP instance. It is a limitation of Edge Data Store that it must reside on the same host as any system that connects to it with OMF.
PI Connector Relay¶
The PI Connector Relay has been discontinued by OSIsoft. All new deployments should use the PI Web API endpoint. Existing installations will still be supported. The PI Connector Relay was the original mechanism by which OMF data could be ingesting into a PI Server. To use the PI Connector Relay, open and sign into the PI Relay Data Connection Manager.
|
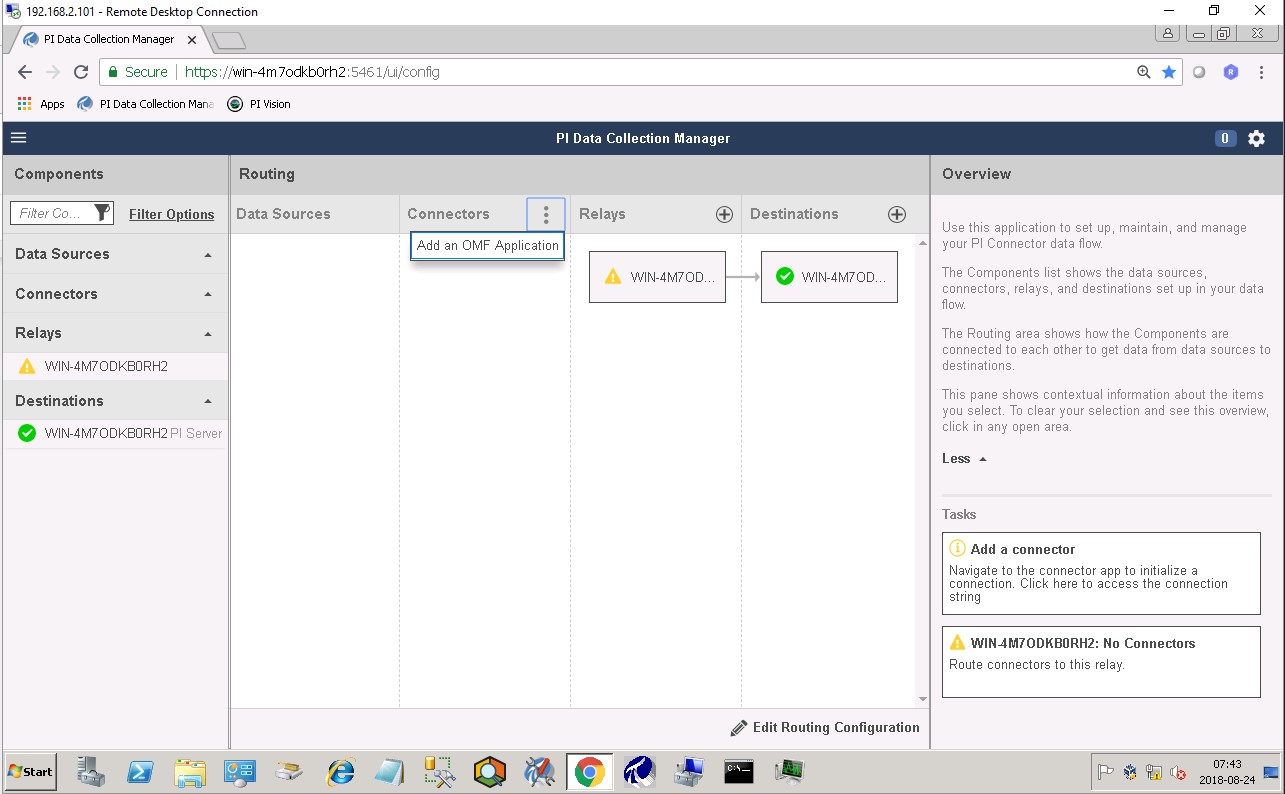
To add a new connector for the FogLAMP system, click on the drop down menu to the right of “Connectors” and select “Add an OMF application”. Add and save the requested configuration information.
|

Connect the new application to the PI Connector Relay by selecting the new FogLAMP application, clicking the check box for the PI Connector Relay and then clicking “Save Configuration”.
|
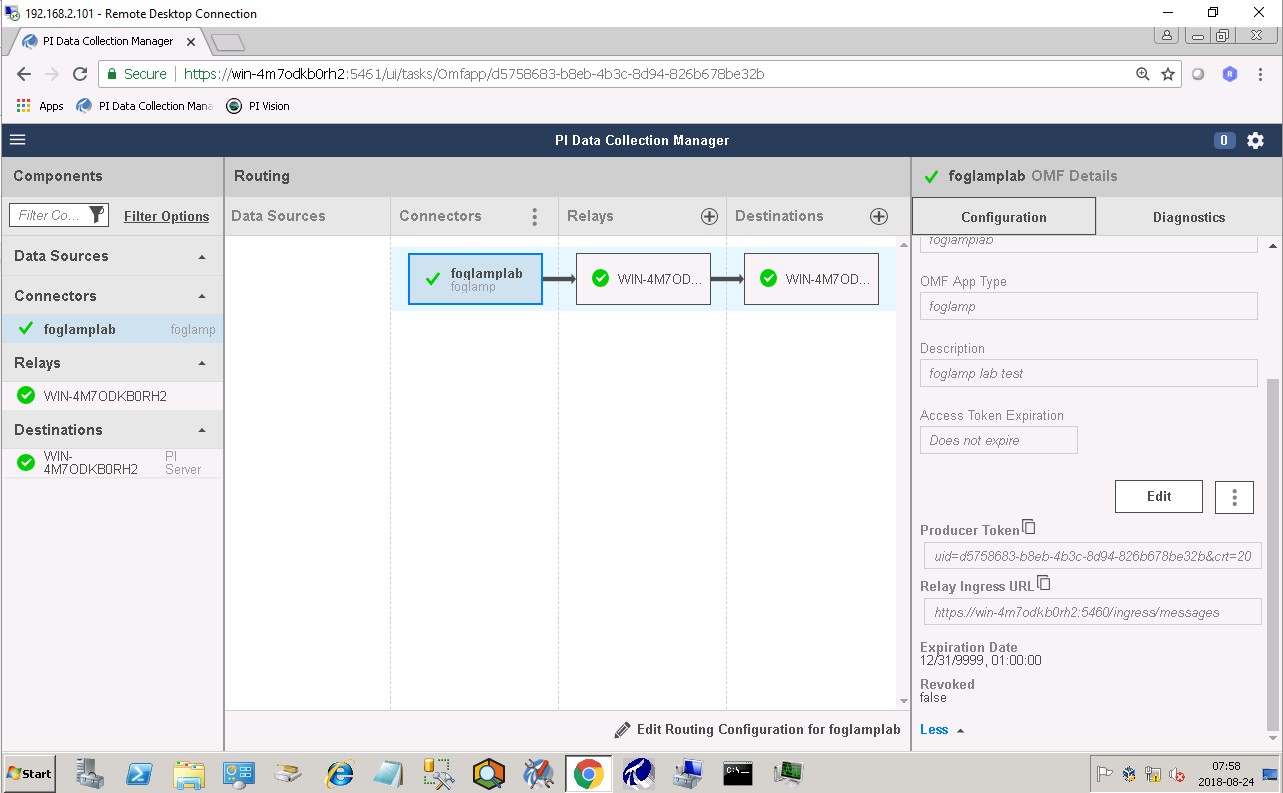
Finally, select the new FogLAMP application. Click “More” at the bottom of the Configuration panel. Make note of the Producer Token and Relay Ingress URL.
Now go to the FogLAMP user interface, create a new North instance and select the “OMF” plugin on the first screen. Continue with the configuration, choosing the connector relay as the end point to be connected.
OSIsoft Cloud Services¶
The original cloud services from OSIsoft, this has now been superseded by AVEVA Data Hub, and should only be used to support existing workloads. All new installations should use AVEVA Data Hub.
Configuration¶
The configuration of the plugin is split into a number of tabs in order to reduce the size of each set of values to enter. Each tab contains a set of related items.
Basic: This tab contains the base set of configuration items that are most commonly changed.
Asset Framework: The configuration that impacts the location with the asset framework in which the data will be placed.
Authentication: The configuration required to authenticate with the OMF end point.
Cloud: Configuration specific to using the cloud end points for OCS and ADH.
Connection: This tab contains the configuration items that can be used to tune the connection to the OMF end point.
Formats & Types: The configuration relating to how types are used and formatted with the OMF data.
Advanced Configuration: Configuration of the service or task that is supporting the OMF plugin.
Security Configuration: The configuration options that impact the security of the service that is running OMF.
Developer: This tab is only visible if the developer features of FogLAMP have been enabled and will give access to the features aimed at a plugin or pipeline developer.
Basic¶
The Basic tab contains the most commonly modified items
|
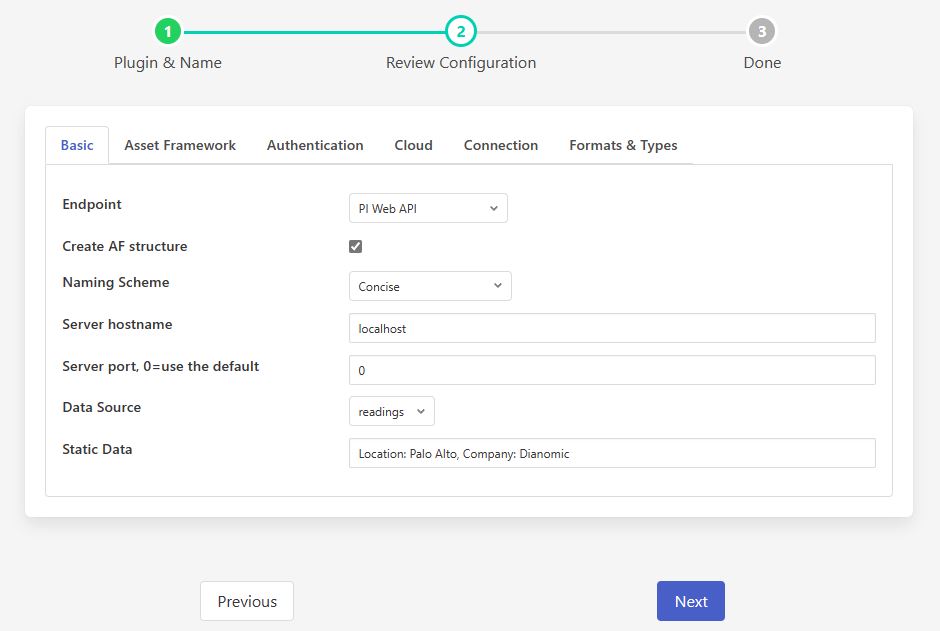
Endpoint: The type of OMF end point we are connecting with. The options available are
PI Web API - A connection to a PI Server that supports the OMF option of the PI Web API. This is the preferred mechanism for sending data to a PI Server.
AVEVA Data Hub - The AVEVA cloud service.
Connector Relay - The previous way to send data to a PI Server before PI Web API supported OMF. This should only be used for older PI Servers that do not have the support available within PI Web API.
OSIsoft Cloud Services - The original OSIsoft cloud service, this is currently being replaced with the AVEVA Data Hub.
Edge Data Store - The OSIsoft Edge Data Store
Create AF Structure: Used to control if Asset Framework structure messages are sent to the PI Server. If this is turned off then the data will not be placed in the Asset Framework.
Naming scheme: Defines the naming scheme to be used when creating the PI points in the PI Data Archive. See Naming Scheme.
Server hostname: The hostname or address of the OMF end point. This is only valid if the end point is a PI Server either with PI Web API or the Connector Relay. This is normally the same address as the PI Server.
Server port: The port the PI Web API OMF endpoint is listening on. Leave as 0 if you are using the default port.
Data Source: Defines which data is sent to the OMF end point. The options available are
readings - The data that has been ingested into FogLAMP via the South services.
statistics - FogLAMP’s internal statistics.
Static Data: Data to include in every reading sent to OMF. For example, you can use this to specify the location of the devices being monitored by the FogLAMP server.
Data Stream Name Delimiter: The plugin creates Container names by concatenating Asset and Datapoint names separated by this single-character delimiter. The default delimiter is a dot (“.”).
Action Code for Data Messages: Defines the action code in the HTTP header when sending OMF Data messages.
All OMF messages must have an action code in the HTTP header which defines how the server should process the OMF message. For Data messages, the default action code is update which means that the server should update the data value if there is already a value at the passed timestamp. If there is no value at the passed timestamp, the data value is inserted into the server’s data archive. If the passed data value is newer than the server’s snapshot, the new value is processed by the server’s compression algorithm. The action code of update is the default and should generally be left unchanged.
The one exception is if the PI Buffer Subsystem is used to buffer data sent to the PI Data Archive. Because of an issue with the PI Buffer Subsystem, OMF data sent with an action code of update is converted to the PI Data Archive’s internal replace storage code. The replace storage code causes the PI Data Archive’s compression algorithm to be bypassed. When using the PI Buffer Subsystem, set the action code to create which will allow new data to be compressed normally. One disadvantage of the create action code is that multiple values with the same timestamp will all be stored.
Enable Tracing: The Enable Tracing flag allows users to toggle the Tracing functionality on or off. If enabled, a detailed tracing of OMF messages will be written to logs/debug-trace/omf.log file in FogLAMP data directory.

Asset Framework¶
The OMF plugins has the ability to interact with the PI Asset Framework and put data into the desired locations within the asset framework. It allows a default location to be specified and also a set of rules to be defined that will override that default location.
|
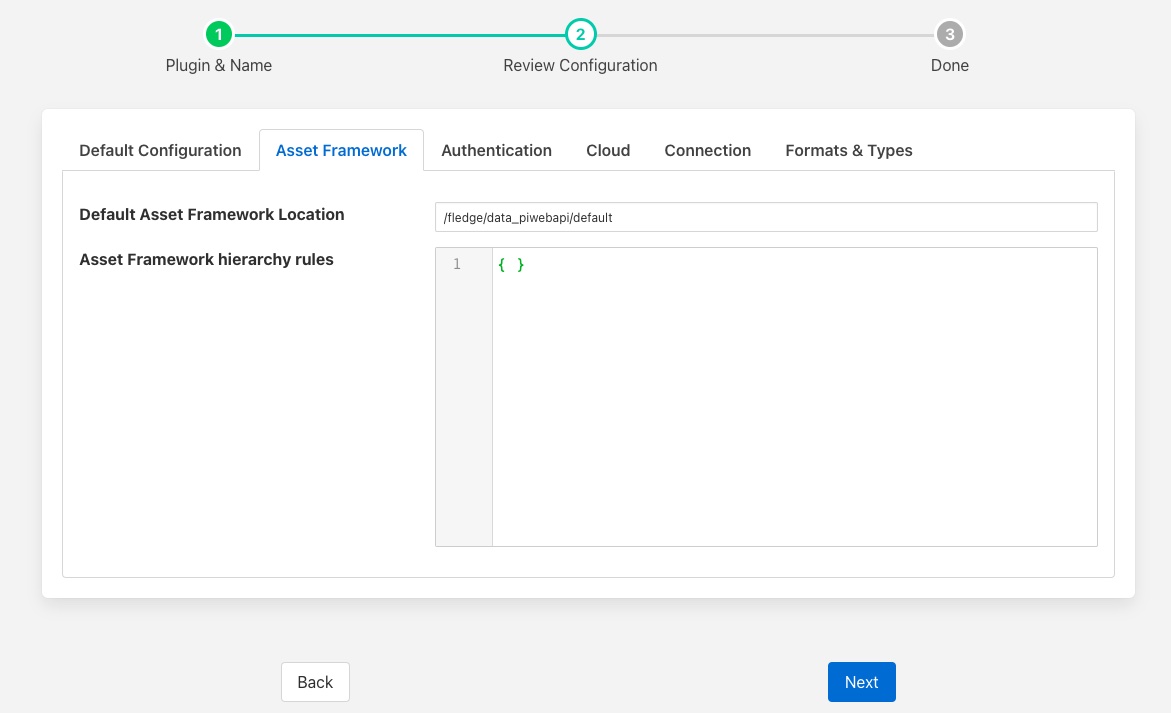
Default Asset Framework Location: The location in the Asset Framework hierarchy into which the data will be inserted. All data will be inserted at this point in the Asset Framework hierarchy unless a later rule overrides this. Note this field does not include the name of the target Asset Framework Database; the target database is defined on the PI Web API server by the PI Web API Admin Utility.
Asset Framework Hierarchies Rules: A set of rules that allow specific readings to be placed elsewhere in the Asset Framework. These rules can be based on the name of the asset itself or some metadata associated with the asset. See Asset Framework Hierarchy Rules.
Authentication¶
The Authentication tab allows the configuration of authentication between the OMF plugin and the OMF endpoint.
|
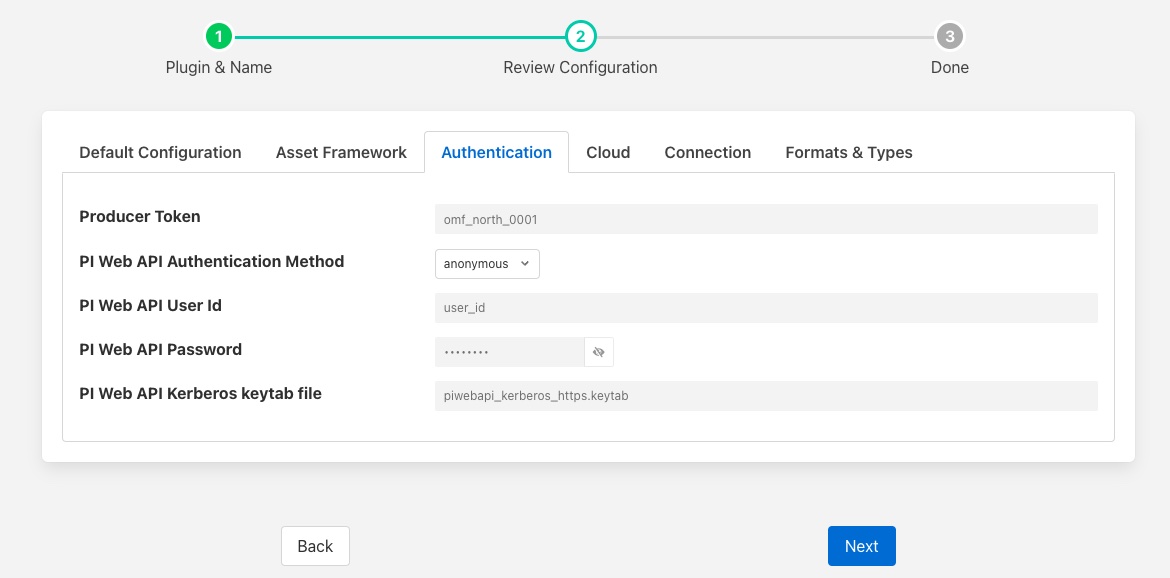
Producer Token: The Producer Token provided by the PI Relay Data Connection Manager. This is only required when using the older Connector Relay end point for sending data to a PI Server.
PI Web API Authentication Method: The authentication method to be used:
anonymous - Anonymous equates to no authentication.
basic - basic authentication requires a user name and password
kerberos - Kerberos allows integration with your Single Sign-On environment.
PI Web API User Id: For Basic authentication, the user name to authenticate with the PI Web API.
PI Web API Password: For Basic authentication, the password of the user we are using to authenticate.
PI Web API Kerberos keytab file: The Kerberos keytab file used to authenticate.
Cloud¶
The Cloud tab contains configuration items that are required if the chosen OMF end point is either AVEVA Data Hub or OSIsoft Cloud Services.
|
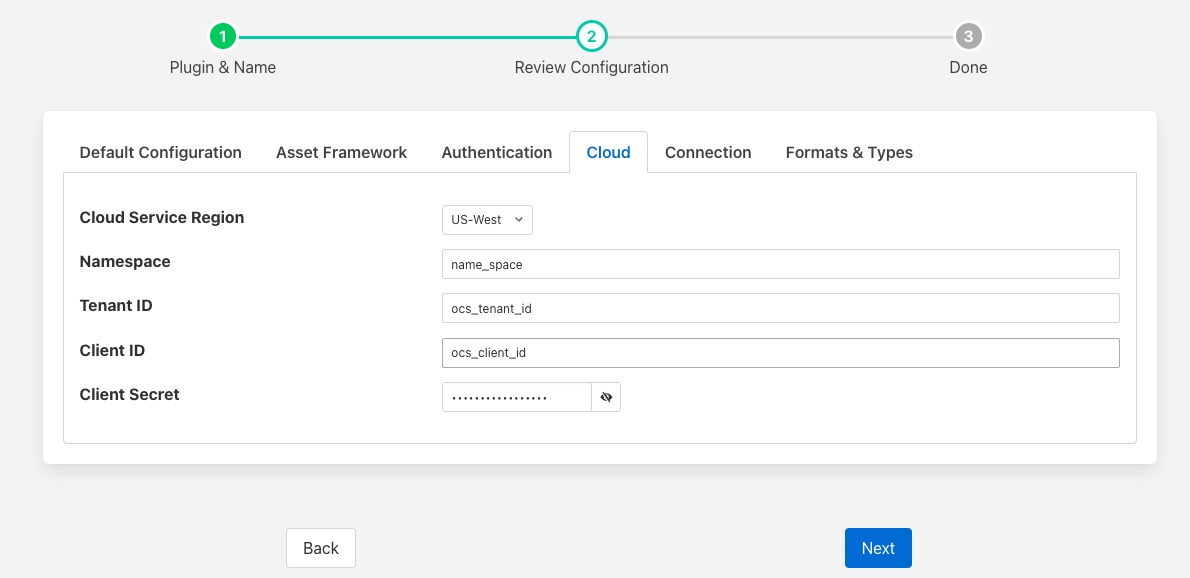
Cloud Service Region: - The region in which your AVEVA Data Hub or OSIsoft Cloud Services service is located.
Namespace: Your namespace within the AVEVA Data Hub or OSIsoft Cloud Service.
Tenant ID: Your AVEVA Data Hub or OSIsoft Cloud Services Tenant ID for your account.
Client ID: Your AVEVA Data Hub or OSIsoft Cloud Services Client ID for your account.
Client Secret: Your AVEVA Data Hub or OSIsoft Cloud Services Client Secret.

Connection¶
The Connection tab allows a set of tuning parameters to be set for the connection from the OMF plugin to the OMF End point.
|
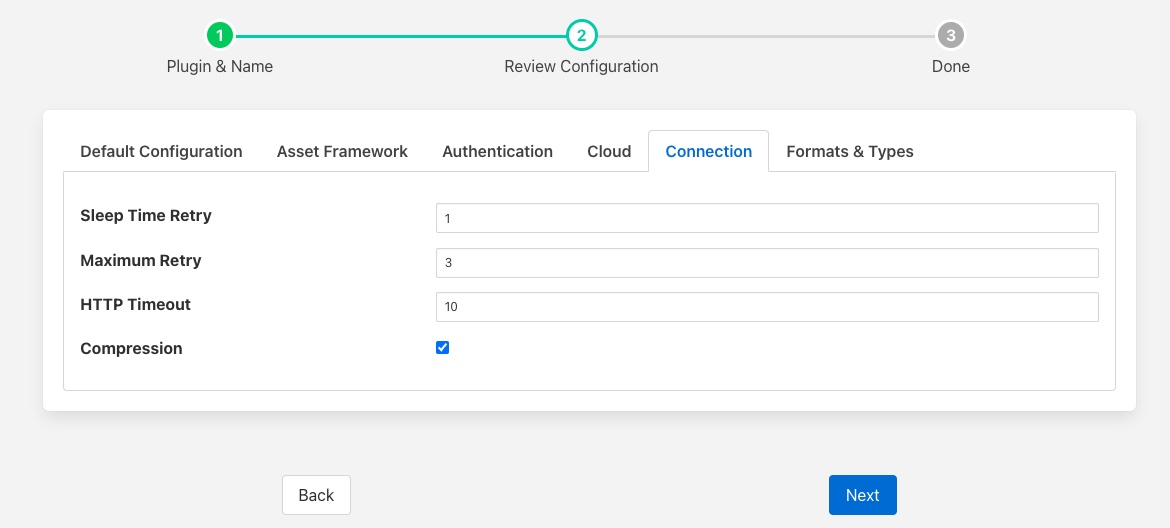
Sleep Time Retry: Number of seconds to wait before retrying the connection (FogLAMP doubles this time after each failed attempt).
Maximum Retry: Maximum number of times to retry connecting to the OMF Endpoint.
HTTP Timeout: Number of seconds to wait before FogLAMP will time out an HTTP connection attempt.
Compression: Compress the readings data before sending them to the OMF endpoint.
Formats & Types¶
The Formats & Types tab provides a means to specify the detail types that will be used and the way complex assets are mapped to OMF types to also be configured. See the section Numeric Data Types for more information on configuring data types.
|
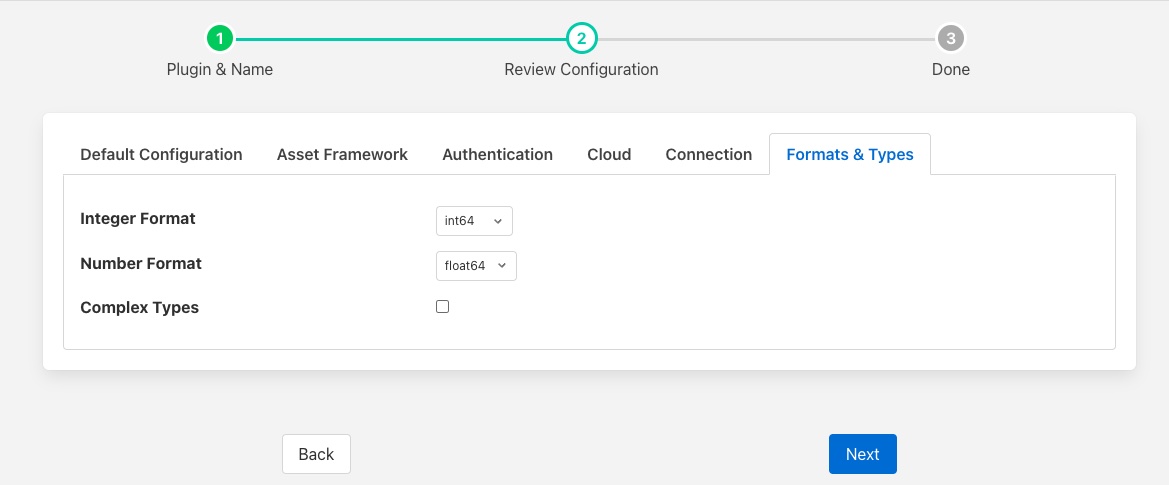
Integer Format: Used to match FogLAMP data types to the data type configured in PI. This defaults to int64 but may be set to any OMF data type compatible with integer data, e.g. int32.
Number Format: Used to match FogLAMP data types to the data type configured in PI. The default is float64 but may be set to any OMF datatype that supports floating point values.
Complex Types: Versions of the OMF plugin prior to 2.1 support complex types in which each asset would have a corresponding OMF type created for it. With the introduction of OMF Version 1.2 support in version 2.1.0 of the plugin support has been added for linked types. These are more versatile and allow for asset structures to change dynamically. The linked types are now the default, however setting this option can force the older complex types to be used. See Linked Types. Versions of the PI Server from 2020 or before will always use the complex types. The plugin will normally automatically detect this, however if the detection does not correctly enforce this setting then this option should be enabled by the user.
Naming Scheme¶
The naming of objects in the Asset Framework and of the attributes of those objects has a number of constraints that need to be understood when storing data into a PI Server using OMF. An important factor in this is the stability of your data structures. If you have objects in your environment that are likely to change, you may wish to take a different naming approach. Examples of changes are a difference in the number of attributes between readings, and a change in the data types of attributes.
This occurs because of a limitation of the OMF interface to the PI Server. Data is sent to OMF in a number of stages. One of these is the definition of the Types used to create AF Element Templates. OMF uses a Type to define an AF Element Template but once defined it cannot be changed. If an updated Type definition is sent to OMF, it will be used to create a new AF Element Template rather than changing the existing one. This means a new AF Element Template is created each time a Type changes.
The OMF plugin names objects in the Asset Framework based upon the asset name in the reading within FogLAMP. Asset names are typically added to the readings in the south plugins, however they may be altered by filters between the south ingest and the north egress points in the data pipeline. Asset names can be overridden using the OMF Hints mechanism described below.
The attribute names used within the objects in the PI System are based on the names of the datapoints within each Reading within FogLAMP. Again OMF Hints can be used to override this mechanism.
The naming used within the objects in the Asset Framework is controlled by the Naming Scheme option:
- Concise
No suffix or prefix is added to the asset name and property name when creating objects in the Asset Framework and PI Points in the PI Data Archive. However, if the structure of an asset changes a new AF Element Template will be created which will have the suffix -type*x* appended to it.
- Use Type Suffix
The AF Element names will be created from the asset names by appending the suffix -type*x* to the asset name. If the structure of an asset changes a new AF Element name will be created with an updated suffix.
- Use Attribute Hash
AF Attribute names will be created using a numerical hash as a prefix.
- Backward Compatibility
The naming reverts to the rules that were used by version 1.9.1 and earlier of FogLAMP: both type suffixes and attribute hashes will be applied to the name.
Asset Framework Hierarchy Rules¶
The Asset Framework rules allow the location of specific assets within the Asset Framework to be controlled. There are two basic types of hint:
Asset name placement: the name of the asset determines where in the Asset Framework the asset is placed,
Meta data placement: metadata within the reading determines where the asset is placed in the Asset Framework.
The rules are encoded within a JSON document. This document contains two properties in the root of the document: one for name-based rules and the other for metadata based rules.
{
"names" :
{
"asset1" : "/Building1/EastWing/GroundFloor/Room4",
"asset2" : "Room14"
},
"metadata" :
{
"exist" :
{
"temperature" : "temperatures",
"power" : "/Electrical/Power"
},
"nonexist" :
{
"unit" : "Uncalibrated"
}
"equal" :
{
"room" :
{
"4" : "ElecticalLab",
"6" : "FluidLab"
}
}
"notequal" :
{
"building" :
{
"plant" : "/Office/Environment"
}
}
}
}
The name type rules are simply a set of asset name and Asset Framework location pairs. The asset names must be complete names; there is no pattern matching within the names.
The metadata rules are more complex. Four different tests can be applied:
exists: This test looks for the existence of the named datapoint within the asset.
nonexist: This test looks for the lack of a named datapoint within the asset.
equal: This test looks for a named datapoint having a given value.
notequal: This test looks for a name datapoint having a value different from that specified.
The exist and nonexist tests take a set of name/value pairs that are tested. The name is the datapoint name to examine and the value is the Asset Framework location to use. For example
"exist" :
{
"temperature" : "temperatures",
"power" : "/Electrical/Power"
}
If an asset has a datapoint called temperature in will be stored in the AF hierarchy temperatures, if the asset had a datapoint called power the asset will be placed in the AF hierarchy /Electrical/Power.
The equal and notequal tests take an object as a child, the name of the object is datapoint to examine, the child nodes a sets of values and locations. For example
"equal" :
{
"room" :
{
"4" : "ElectricalLab",
"6" : "FluidLab"
}
}
In this case if the asset has a datapoint called room with a value of 4 then the asset will be placed in the AF location ElectricalLab, if it has a value of 6 then it is placed in the AF location FluidLab.
If an asset matches multiple rules in the ruleset it will appear in multiple locations in the hierarchy, the data is shared between each of the locations.
If an OMF Hint exists within a particular reading this will take precedence over generic rules.
The AF location may be a simple string or it may also include substitutions from other datapoints within the reading. For example of the reading has a datapoint called room that contains the room in which the readings was taken, an AF location of /BuildingA/${room} would put the reading in the Asset Framework using the value of the room datapoint. The reading
"reading" : {
"temperature" : 23.4,
"room" : "B114"
}
would be put in the AF at /BuildingA/B114 whereas a reading of the form
"reading" : {
"temperature" : 24.6,
"room" : "2016"
}
would be put at the location /BuildingA/2016.
It is also possible to define defaults if the referenced datapoint is missing. In our example above if we used the location /BuildingA/${room:unknown} a reading without a room datapoint would be placed in /BuildingA/unknown. If no default is given and the data point is missing then the level in the hierarchy is ignore. E.g. if we use our original location /BuildingA/${room} and we have the reading
"reading" : {
"temperature" : 22.8,
}
this reading would be stored in /BuildingA.
OMF Hints¶
The OMF plugin also supports the concept of hints in the actual data that determine how the data should be treated by the plugin. Hints are encoded in a specially name datapoint within the asset, OMFHint. The hints themselves are encoded as JSON within a string.
Number Format Hints¶
A number format hint tells the plugin what number format to use when inserting data into the PI Server. The following will cause all numeric data within the asset to be written using the format float32. See the section Numeric Data Types.
"OMFHint" : { "number" : "float32" }
The value of the number hint may be any numeric format that is supported by the PI Server.
Integer Format Hints¶
An integer format hint tells the plugin what integer format to use when inserting data into the PI Server. The following will cause all integer data within the asset to be written using the format integer32. See the section Numeric Data Types.
"OMFHint" : { "integer" : "integer32" }
The value of the number hint may be any numeric format that is supported by the PI Server.
Type Name Hints¶
A type name hint specifies that a particular name should be used when defining the name of the type that will be created to store the object in the Asset Framework. This will override the Naming Scheme currently configured.
"OMFHint" : { "typeName" : "substation" }
Type Hint¶
A type hint is similar to a type name hint, but instead of defining the name of a type to create it defines the name of an existing type to use. The structure of the asset must match the structure of the existing type with the PI Server, it is the responsibility of the person that adds this hint to ensure this is the case.
"OMFHint" : { "type" : "pump" }
Note
This hint only has meaning when using the complex type legacy mode with this plugin.
Tag Name Hint¶
Specifies that a specific tag name should be used when storing data in the PI Server.
"OMFHint" : { "tagName" : "AC1246" }
Source Hint¶
The default data source that is associated with tags in the PI Server is FogLAMP, however this can be overridden using the data source hint. This hint may be applied to the entire asset or to specific datapoints within the asset.
"OMFHint" : { "source" : "FogLAMP23" }
Datapoint Specific Hint¶
Hints may also be targeted to specific data points within an asset by using the datapoint hint. A datapoint hint takes a JSON object as its value; the object defines the name of the datapoint and the hint to apply.
"OMFHint" : { "datapoint" : { "name" : "voltage:, "number" : "float32" } }
The above hint applies to the datapoint voltage in the asset and applies a number format hint to that datapoint.
If more than one datapoint within a reading is required to have OMF hints attached to them this may be done by using an array as a child of the datapoint item.
"OMFHint" : { "datapoint" : [
{ "name" : "voltage:, "number" : "float32", "uom" : "volt" },
{ "name" : "current:, "number" : "uint32", "uom" : "milliampere }
]
}
The example above attaches a number hint to both the voltage and current datapoints and to the current datapoint. It assigns a unit of measure of milliampere. The unit of measure for the voltage is set to be volts.
Asset Framework Location Hint¶
An Asset Framework location hint can be added to a reading to control the placement of the asset within the Asset Framework. This hint overrides the path in the Default Asset Framework Location for the reading. An Asset Framework hint would be as follows:
"OMFHint" : { "AFLocation" : "/UK/London/TowerHill/Floor4" }
Note the following when defining an AFLocation hint:
An asset name in a FogLAMP Reading is used to create an AF Element in the OSIsoft Asset Framework. Time series data streams become AF Attributes of that AF Element. This means these AF Attributes are mapped to PI Points using the OSIsoft PI Point Data Reference.
Deleting the original Reading AF Element is not recommended; if you delete a Reading AF Element, the OMF North plugin will not recreate it.
If you wish to move a Reading AF Element, you can do this with the PI System Explorer. Right-click on the AF Element that represents the Reading AF Element. Choose Copy. Select the AF Element that will serve as the new parent of the Reading AF Element. Right-click and choose Paste or Paste Reference. Note that PI System Explorer does not have the traditional Cut function for AF Elements.
- For Linked Types
If you define an AF Location hint after the Reading AF Element has been created in the default location, a reference will be created in the location defined by the hint.
If an AF Location hint was in place when the Reading AF Element was created and you then disable the hint, a reference will be created in the Default Asset Framework Location.
If you edit the AF Location hint, the Reading AF Element not move. A reference to the Reading AF Element will be created in the new location.
- For Complex Types
If you disable the OMF Hint filter, the Reading AF Element will not move.
If you edit the AF Location hint, the Reading AF Element will move to the new location in the AF hierarchy.
No references are created.
Unit Of Measure Hint¶
A unit of measure, or uom hint is used to associate one of the units of measurement defined within your PI Server with a particular data point within an asset.
"OMFHint" : { "datapoint" : { "name" : "height:, "uom" : "meter" } }
Minimum Hint¶
A minimum hint is used to associate a minimum value in the PI Point created for a data point.
"OMFHint" : { "datapoint" : { "name" : "height:, "minimum" : "0" } }
Maximum Hint¶
A maximum hint is used to associate a maximum value in the PI Point created for a data point.
"OMFHint" : { "datapoint" : { "name" : "height:, "maximum" : "100000" } }
Interpolation¶
The interpolation hint sets the interpolation value used within the PI Server, interpolation values supported are continuous, discrete, stepwisecontinuousleading, and stepwisecontinuousfollowing.
"OMFHint" : { "datapoint" : { "name" : "height:, "interpolation" : "continuous" } }
Adding OMF Hints¶
An OMF Hint is implemented as a string data point on a reading with the data point name of OMFHint. It can be added at any point in the processing of the data, however a specific plugin is available for adding the hints, the OMFHint filter plugin.
Numeric Data Types¶
Configuring Numeric Data Types¶
It is possible to configure the exact data types used to send data to the PI Server using OMF. To configure the data types for all integers and numbers (that is, floating point values), you can use the Formats & Types tab in the FogLAMP GUI. To influence the data types for specific assets or datapoints, you can create an OMFHint of type number or integer.
You must create your data type configurations before starting your OMF North plugin instance. After your plugin has run for the first time, OMF messages sent by the plugin to the PI Server will cause AF Attributes and PI Points to be created using data types defined by your configuration. The data types of the AF Attributes and PI Points will not change if you edit your OMF North plugin instance configuration. For example, if you disable an integer OMFHint, you will change the OMF messages sent to PI but the data in the messages will no longer match the AF Attributes and PI Points in your PI Server.
Detecting the Data Type Mismatch Problem¶
Editing your data type choices in OMF North will cause the following messages to appear in the System Log:
WARNING: The OMF endpoint reported a conflict when sending containers: 1 messages
WARNING: Message 0: Error, A container with the supplied ID already exists, but does not match the supplied container.,
These errors will cause the plugin to retry sending container information a number of times determined the Maximum Retry count on the Connection tab in the FogLAMP GUI. The default is 3. The plugin will then send numeric data values to PI continuously. Unfortunately, the PI Web API returns no HTTP error when this happens so no messages are logged. In PI, you will see that timestamps are correct but all numeric values are zero.
Recovering from the Data Type Mismatch Problem¶
As you experiment with configurations, you may discover that your original assumptions about your data types were not correct and need to be changed. It is possible to repair your PI Server so that you do not need to discard your AF Database and start over. This is the procedure:
Shut down your OMF North instance.
Using PI System Explorer, locate the problematic PI Points. These are points with a value of zero. The PI Points are mapped to AF Attributes using the PI Point Data Reference. For each AF Attribute, you can see the name of the PI Point in the Settings pane.
Using PI System Management Tools (PI SMT), open the Point Builder tool (under Points) and locate the problematic PI Points.
In the General tab in the Point Builder, locate the Extended Descriptor (Exdesc). It will contain a long character string with several OMF tokens such as OmfPropertyIndexer, OmfContainerId and OmfTypeId. Clear the Excdesc field completely and save your change.
Start up your OMF North instance.
Clearing the Extended Descriptor will cause OMF to “adopt” the PI Point. OMF will update the Extended Descriptor with new values of the OMF tokens. Watch the System Log during startup to see if any problems occur.
Further Troubleshooting¶
If you are unable to locate your problematic PI Points using the PI System Explorer, or if there are simply too many of them, there are advanced techniques available to troubleshoot and repair your system. Contact Technical Support for assistance.
Linked Types¶
Versions of this plugin prior to 2.1.0 created a complex type within OMF for each asset that included all of the data points within that asset. This suffered from a limitation in that readings had to contain values for all of the data points of an asset in order to be accepted by the OMF end point. Following the introduction of OMF version 1.2 it was possible to use the linking features of OMF to avoid the need to create complex types for an asset and instead create empty assets and link the data points to this shell asset. This allows readings to only contain a subset of datapoints and still be successfully sent to the PI Server, or other end points.
As of version 2.1.0 this linking approach is used for all new assets created, if assets exist within the PI Server from versions of the plugin prior to 2.1.0 then the older, complex types will be used. It is possible to force the plugin to use complex types for all assets, both old and new, using the configuration option. It is also to force a particular asset to use the complex type mechanism using an OMFHint.
OMF Version Support¶
To date, AVEVA has released three versions of the OSIsoft Message Format (OMF) specification: 1.0, 1.1 and 1.2. The OMF Plugin supports all three OMF versions. The plugin will determine the OMF version to use by reading product version information from the AVEVA data destination system. These are the OMF versions the plugin will use to post data:
OMF Version |
PI Web API |
Edge Data Store (EDS) |
|---|---|---|
1.2 |
|
|
1.1 |
||
1.0 |
|
|
The AVEVA Data Hub (ADH) is cloud-deployed and is always at the latest version of OMF support which is 1.2. This includes the legacy OSIsoft Cloud Services (OCS) endpoints.